Infrastructure for a Bibliographic Network
In the quarter of a century that Index Data has been providing software solutions to libraries, one of the most common tasks we are asked to do is aggregate the holdings of groups of libraries, and among our bag of tricks is software that builds unified catalogs (Zebra) and federated search catalogs (MasterKey). As is always the case, the progress of technology means that what was new and innovative yesterday is necessary and
The use cases for a Bibliographic Network are varied. Some are looking for a mechanism to pool the records from consortia members so those records can be inserted into a member library’s self-hosted discovery layer as options presented to a patron for requesting. Others want to replace a consortium’s staff-mediated ILL system with a patron-initiated request and delivery system. Another group of libraries wants quick access to the collection retention decisions of peer libraries. Each of these cases presumes the existence of a shared index. And in maintaining a shared index recognizing that not everyone will arrive there at the same time, and that multiple parallel models, data formats, and systems will continue to exist, perhaps indefinitely.
As we have been thinking about this at Index Data, we designed a software system that can be deployed by any library, organization, or company to build an aggregation of metadata spanning an arbitrary group of member libraries. It can also be used to further share this metadata and create aggregations across consortia and group memberships, thus advancing experimentation already underway in the library community. Called the “Bibliographic Network”, the software system provides the means to build indexes as needed as well as to publish, in flat files or through linked data mechanisms, sets of bibliographic and authority data at any point in the network.
Conceptual Model
For the purpose of this discussion, we view the space that we are modeling as the curation and sharing of bibliographic metadata in terms of entities such as titles and authors. The BIBFRAME model provides a convenient set of entities that map well to traditional bibliographic description: Works, Instances (i.e. editions, different formats), Items (physical, identifiable objects), Agents, Subjects, and Events. In practice, metadata about these entities can be exchanged using different mechanisms such as MARC file batch load, publishing BIBFRAME entities on the web, or through schema.org statements. Conceptually, we are looking to create software to help with the curation (and indexing!) of these entities. Crosswalks and mappings to and from different representations will be required to support different use cases, but we are not in most of this document making assumptions about how the data might be stored and managed.
When thinking about the bibliographic ecosystem – and in particular a move towards a linked data ecosystem where maximum re-use of once-published entities is desirable (as opposed to each library copying and re-publishing all of the same bibliographic statements) – it is tempting to seek an ordered universe of actors with discretely scoped responsibilities:
In such a model, national libraries might be responsible for cataloging their national bibliography (all original publications in that country), while libraries might fill in the gaps through original cataloging and consortia might serve to aggregate and consolidate metadata across member libraries. In a perfectly organized universe, no title would be redundantly (copy) cataloged, and everyone would share the same universe of bibliographic metadata, with clear responsibilities and chains of provenance for individual bibliographic statements. Holdings information might be aggregated at any level, i.e. consortia might wish to aggregate detailed holdings information about member libraries. National or international utilities and agencies might choose to focus on metadata and not address holdings information.
In the real world, though, such a state is practically unattainable, and the path towards even a partial realization is unclear:
- Different national libraries have vastly different mandates and resources and organizations are rarely limited to a single role or a single set of clearly defined relationships.
- National and state libraries are working libraries, as well as serving the role of utilities for other libraries.
- Libraries frequently belong to more than one consortium.
The potential for confusion and inefficiency is high, especially since today these roles are poorly defined and existing software systems do not support them well.
However, we believe that it is possible to create a set of software and services that can support the concrete needs of today, while also carving an easier path towards a more efficient organization of the work of curating our bibliographic universe.
Bibliographic Ecosystem as a Network
As suggested above, a simple hierarchical, tree-structured view of the library universe breaks down because libraries often play more than one role. We propose to model the ecosystem instead as a set of nodes in a graph or network, with each node corresponding to a library or organization, and the edges corresponding to relationships between libraries determined by functional roles. We propose the following as a starting point for a set of roles germane to the collective maintenance of bibliographic metadata:
- Contribute: A library (or other organization) engages in original cataloging, creating new entities when suitable ones cannot be identified in the network.
- Aggregate: An organization gathers together metadata from other organizations. Aggregation is the complementary operation to syndication (described below). The aggregation function includes disambiguation, i.e. an attempt to resolve matching/overlapping entities.
- Index: An organization creates an index of metadata that it has contributed and/or aggregated. Optionally, an index may be made available to others for re-use.
- Publish: An organization publishes bibliographic entities that it has contributed or aggregated. For example, a consortium may publish the combined holdings of its member libraries. Publishing implies potentially minting new permanent identities (URIs) and should be done with care and in concert with local and national partner libraries.
- Syndicate: An organization makes its set of metadata (contributed and/or aggregated) available to other nodes, e.g. to support a shared index or union catalog. This implies supporting a harvesting or ‘push’ mechanism to share updates.
In this model, the node (library, consortium, utility, etc) and its relationships to other nodes become central to how the system functions. Each library might aggregate from multiple other nodes and share metadata with multiple other nodes:
Consider use cases, or patterns that might emerge from the basic building blocks outlined above:
- A small library might use an index made available by a consortium or larger library, either through an API, through download into a discovery layer, or directly through a discovery layer made available by the larger library.
- The same library might Contribute original metadata and Syndicate it for ingestion into a larger aggregation in a consortium or state library
- A consortium might Aggregate metadata from member libraries and other consortia, national libraries, etc. It might Index all of this metadata, and Syndicate or Publish metadata to a national library or partner consortia
- A national library might play all of these roles concurrently within its national ecosystem as well as with partner national libraries
What emerges is a network of organizations collaborating more or less closely to curate a combined set of bibliographic metadata (including authorities, etc). The gestalten network(s) might be highly organized or they might form locally organized regions (i.e. within consortia) surrounded by looser structures. Representing Publish as a separate function allows a sub-community to be selective about when to mint new entities with discrete URIs. But by defining possible roles and relationships, and, crucially, by providing software that makes it easy to adopt these roles, a development in this area might both address immediate short-term needs by solving concrete problems, while also carving a path towards a higher level of organization and re-use.
Implementation
The five roles/relationships described above should ideally be established entirely in terms of open interfaces and standards. In practice, the roles described could all be supported by different combinations of software or modules that form parts of different systems. We will, however, propose a modular open source solution that makes it easy for an organization to establish a node in a bibliographic data network such as the one described here, and support the different roles as well as relationships with other entities. This software can be seen as an enabling factor, so that the network model can be implemented in specific communities (such as consortia), but also as a platform for exploring and experimenting with new use cases in a controlled environment.
We are working on an implementation of the Bibliographic Network based on the Okapi-Stripes Platform from the FOLIO Project. The Okapi-Stripes Platform was originally developed to be the infrastructure for the FOLIO Project. It is seen now as a generally useful infrastructure component for other projects, and the Open Library Foundation (OLF) is considering the separation of the Platform components into a distinct OLF community project. The “FOLIO LSP” suite of apps on the Okapi-Stripes Platform intended to replace the functionality of an integrated library system is the most well-known part of the project. As a platform, it is possible to create other apps without any connection to the LSP suite and to borrow individual apps without depending on others. Our implementation uses the Okapi-Stripes Platform and borrows/adapts selected FOLIO LSP apps without creating a strong dependency between the Bibliographic Network and the LSP project; the projects are separate as it is assumed that many libraries will not use FOLIO LSP as their integrated library system.
A description of the Okapi-Stripes Platform’s relationship to the rest of FOLIO can be found in the FOLIO wiki. Documentation of Okapi (server-side modules) and Stripes (browser-based JavaScript single-page-application) can be found on the FOLIO Developer’s website. However, it should not be necessary to possess deep knowledge of the Okapi-Stripes Platform to understand the high-level architectural concepts presented here.
The Okapi-Stripes Platform is a true multi-tenant application environment for web-based applications, or “apps.” The concept is similar to Google’s office suite and other web-hosted, extensible environments. A tenant is like a workspace in the Platform, which is typically specific to a library or organization. It has its own set of apps, its own users, its own data. Multiple tenants can be hosted in a single installed instance of the Platform.
Each library’s node is instantiated as a tenant in a shared cloud-hosted Okapi-Stripes deployment. Thus, although in principle the ecosystem model is entirely decentralized, it would be simple to co-locate the nodes representing the libraries in a consortium on one single software instance managed by a library or by a consortium. Individual libraries might also choose to run their own nodes, or system vendors might incorporate the functionality and the recommended standard interfaces into library management products.
One of the key design decisions to make when building a solution based on the Platform is the division of functionality into modules or “apps”. These apps can be deployed independently for each tenant, so libraries can adapt an Okapi-Stripes-based solution to their needs by selecting which apps to make use of.
One straightforward architectural interpretation of the model above would be built around a metadata warehouse or inventory representing the universe of metadata known to a given node/library, then use the capabilities in the apps to move data to other nodes in the Bibliographic Network. A library’s node on the Bibliographic Network contains apps corresponding to the five main functions or roles discussed above:
Figure: Overview of a library node:
In the illustration above, the green boxes correspond conceptually to Okapi/Stripes web-apps, with admin-facing user interfaces based on the Stripes React toolkit and Okapi-mediated microservices at the back-end. The Inventory app and associated Summary metadata model and detailed record stores are extant software, made available by the Open Library Foundation under the Apache2 license.
The high-level functionality of the apps (building on the high-level roles described above) are as follows
- ILS Extract: Populate the Inventory with bibliographic data by way of extraction from the library’s ILS through OAI-PMH, scheduled FTP downloads, etc. Depending on the ILS, some periodic manual processing may be unavoidable. Records are pushed into the Inventory by way of an identity resolution function, which looks for duplicate entities as well as entities that already exist in the Inventory (updates). The ILS Extract app performs one half of the Contribute role in the model described above.
- Inventory: An aggregation or warehouse of bibliographic metadata (instances as well as potentially works, agents, places, items), normalized into a common data model for purposes of deduplication and filtering. Original MARC records are stored (in SRS, or Source Record Storage) or externally maintained BIBFRAME records can be linked to. The Inventory app performs the other half of the Contribute role in the model described above.
- Syndicate: Make all or a subset of the Inventory available to other Bibliographic Network nodes (other libraries or a consortial node). This could theoretically be done through any number of mechanisms, but ideally, one which supports incremental updates and a ‘push’ function, so that local changes can be exposed as quickly as possible to partner nodes. ResourceSync is a candidate solution.
- Aggregate: The receiving end of the syndication function. Includes the same identity resolution logic as the ILS extract. This function allows the library to construct a ‘super-inventory’ based on the contents of other library nodes.
- Publish: This app publishes (a part of) the inventory as linked data entities with permanent identifiers, suitable for cross-linking or indexing by web search engines.
- Index: Construct a searchable index of the contents of the inventory using a high-performance indexing engine. This includes a configurable mapping step, and may make use both of the summary record contents and original MARC contents if desired.
An Example Deployment for a Consortium Union Catalog
While the software described here could be deployed by many types of organizations to build different ‘topologies’ of metadata exchanges and aggregations, we offer this proposal for the specific near-term use case of a consortium’s union catalog. Each consortium member will have access to a library node, wherein they can manage the synchronization of their metadata with their ILS, apply filters, and syndicate metadata to a shared consortial node, operated by the consortium or by one library on behalf of the consortium.
Our proposal leverages the multi-tenant capabilities of the Okapi-Stripes and the existing Inventory app of the FOLIO LSP. Each consortium member would be its own tenant on a shared Platform installation (“Member Tenant”). The Member Tenant has:
- the ILS Extract app, adequately configured and provisioned for its particular ILS, to extract and normalize data from the ILS;
- the Inventory app for staging and managing the library’s contribution to the shared dataset; and
- the Syndicate app to make metadata available to the consortial shared aggregation (or possibly to multiple aggregations, if it participates in more than one consortium).
Records from the member’s ILS and other sources would use the ILS Extract app to synchronize holdings information stored in the Inventory module. Records could be synchronized with a handful of mechanisms: regular OAI-PMH or ResourceSync harvests, realtime webhook messages, and comparison from a periodic full databases dump. As a last resort, Index Data can use its Connector Framework web-scraping technology to periodically scan the member’s OPAC. The synchronization mechanism merges bibliographic and holdings records should they come as separate feeds. The ILS Extract app provides a consistent interface between the member’s bibliographic data and the Bibliographic Network, whether such data is loaded in bulk or added/updated/deleted incrementally from the member’s ILS.
Details about the eligibility and availability of a resource for lending can also be stored in the item’s Inventory module record. The ILS Extract app would have a configuration page for mapping which item locations, item types, item formats, and publication years coming from the member’s ILS to a requesting eligibility statement. If item status (checked out, lost, etc.) is available in the real-time feed of records from the member ILS, the Inventory module can also store real-time availability of items in the Member Tenant Inventory module. Between the Member Tenant and the member’s ILS is a variety of mechanisms for determining availability, from Z39.50 connections to use of Index Data’s web-scraping Connector Platform technology. To other applications consuming a real-time-availability request API response, the data provided will be consistent no matter what mechanism is used to determine availability from the member’s ILS.
Changes recorded in each Member Tenant would also be available in that tenant’s Syndicate app to be contributed to the consortial Inventory app running in a separate Okapi-Stripes Platform tenant (the “Consortial Tenant”). That module performs a deduplication/merging algorithm and stores the resulting derivative record in the Consortial Tenant Inventory. A holdings record representing the member’s record is also stored in the Consortial Tenant Inventory module.
The Consortial Tenant aggregates metadata from each member library (and potentially from other sources, e.g. Hathitrust, Internet Archive, Library of Congress, etc). Data would be stored in a shared Inventory, and from there it would be picked up by the Index app to build a searchable index. The consortium might also choose to further syndicate its aggregated metadata set if it works in partnership with other consortia.
Either the individual libraries or the consortia might also choose to use the Publish app (optional) to publish a linked-data representation of the combined metadata set. The syndication/aggregation chain and identity resolution logic should ensure that cross-links between entities are established when needed (either between companion entities like works and instances or between equivalent instances published by different network members).
The following diagram illustrates the flow of data upwards from the individual library nodes with their associated ILSes into the shared warehouse where identity-matched bibliographic instances are maintained. From the shared warehouse, bibliographic data can be indexed, published (as BIBFRAME and/or schema.org) or syndicated to other consortia.
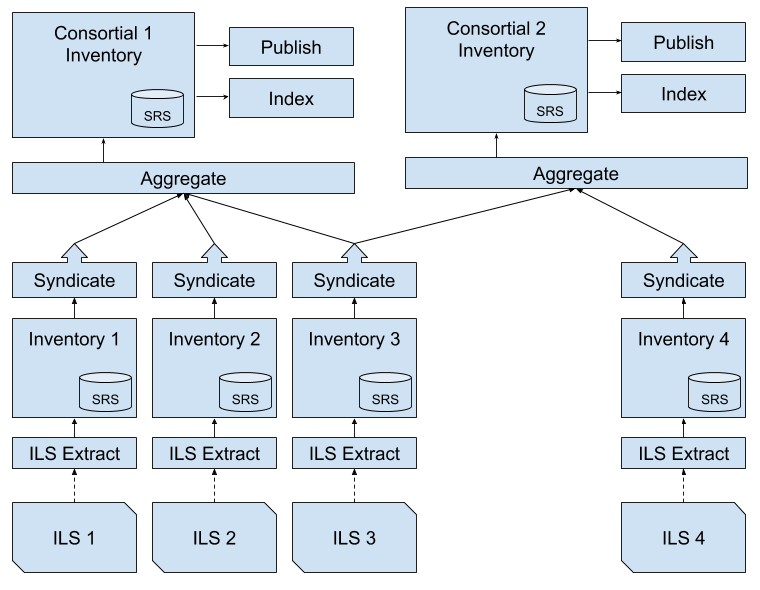
Making the Bibliographic Network
To this point, Index Data has privately shared the conceptual model and implementation details for the Bibliographic Network with a few clients and potential clients, and incorporated feedback into this posting. The concepts were well received enough to seek broader feedback. If you are reading this posting as a result of following a link in an Index Data proposal to your request-for-information and request-for-proposal, please know that this is a starting point for our discussions on how Index Data technology is adaptable to your needs. If this post gets your gears turning and you think this technology can be applied to your use cases, start a conversation with us to learn the state of development for the Bibliographic Network.