Index Data’s Integrated Discovery Model
We are often asked about where we stand on the discussion of central indexing versus broadcast metasearching. Our standard answer: “You probably need some of both” always calls for further explanation. Some time ago, I wrote this up for a potential business partner. If it sounds a little like a marketing spiel… guilty as charged. I hope the content will still seem interesting to some folks thinking about these issues. While our specific approach and technology may be ours alone, the technical issues described here are pretty universal.
It is our thesis that a discovery platform which bases itself wholly on either broadcast metasearching or a centralized harvest-and-index model is inherently limited, as compared to one which seamlessly integrates both. It is our goal to provide a versatile platform, capable of handling very large indexes as well as dynamically searching remote content. Our MasterKey platform is an expression of this idea.
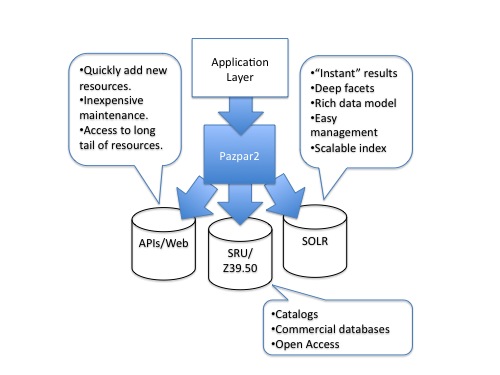
At the core of our platform is Pazpar2, a highly optimized multi-protocol search engine, capable of searching large numbers of heterogeneous resources in parallel. It features a web services API, a data model-agnostic approach to incoming search results, and a cloud-friendly, dynamic configuration mechanism, designed to fit into a variety of application environments. Pazpar2 will search a number of resources concurrently, through multiple protocols, while normalizing and integrating results.
Through its SRU/Z39.50 capability, Pazpar2 can access standards-compliant library catalogs, commercial database providers, etc. Through gateway technologies, it can access a range of other resources: Our SimpleServer provides a simple platform on which to implement gateways to proprietary APIs; our Connector Platform enables access to searchable resources through web-based user interfaces. Facets are constructed on the fly through analysis of incoming results.
Through its integrated Solr client, Pazpar2 can access locally and remotely maintained indexes, taking direct advantage of the capabilities of the Solr search engine to produce high-quality ranked and faceted results with lightning-fast response times.
While accessing a locally operated Solr instance, configured to support an application-specific data model in tandem with Pazpar2, the data normalization step is eliminated, conserving CPU cycles. Facets can be derived directly from the Solr system, eliminating the need to analyze individual records. All local results can be integrated and merged before presentation to the user, providing a highly responsive experience. Data can be freely distributed across Solr instances, allowing for scalability management options in addition to those offered by Solr itself.
Through Pazpar2’s data normalization mechanism, support for remotely maintained Solr instances with arbitrary record models is available, provided that a normalization stylesheet for the data model is provided. This allows for a more sophisticated level of integration with the increasing number of Solr-based applications in the field, and increases the versatility of the platform.
Combining these elements, the user of a hybrid local/remote discovery platform will experience excellent response times on local content, and will see remote results added to the display as soon as they become available (how this is accomplished is a user interface decision).
In addition to the elements described above, the MasterKey platform includes a harvester to schedule and manage harvesting jobs for local indexing purposes (HTTP bulk file download and OAI-PMH supported at present) as well as a service-oriented architecture for managing searchable resources, users, and subscriptions in a hierarchical way designed to address consortial requirements. All components are modular, sharing a service-oriented architecture, and designed to fit into as many architectural and operational contexts as possible.