Clustering Snippets With Carrot2
We’ve been investigating ways we might add result clustering to our metasearch tools. Here’s a short introduction to the topic and to an open source platform for experimenting in this area.
Clustering
Using a search interface that just takes some keywords often leads to miscommunication. The computer has no sense of context and users may not realise their query is ambiguous. When I wanted to represent a matrix in LaTeX typesetting markup, I searched for the keywords ‘latex’ and ‘matrix’. At that moment I wasn’t thinking along the lines of “latex cat-suits, like in the Matrix movies”. But, since one of those movies was just recently out, the search engine included some results of that sort. The information it might use to determine relevance (word frequency, number and recency of links, what people ultimately click on when performing similar searches, etc.) would not be enough to choose which interpretation of my query terms I was interested in.
To aid the user in narrowing results to just those applicable to the context they’re thinking about, a good deal of work has been done in the area of “clustering” searches. The idea is to take the usual flat, one dimensional result list and instead split it into several groups of results corresponding to different categories. Mining data to find patterns has been studied for some time and current work on automatically grouping documents has roots in this research.
One common way to represent a document, both for searching and data mining, is the vector space model. Introduced by Gerard Salton, underappreciated pioneer of text search, the idea is to distil documents down to statistics about the words they contain. Particularly, it involves considering the terms as dimensions so we can apply some handy matrix math to them. Then a document becomes a vector in term-space with a magnitude corresponding to how relevant the document is considered to be to those terms. In other words, a sushi menu would be located further along in the ‘fish’ and ‘rice’ directions than in the ‘dinosaur’ direction.
This kind of bag-of-words model is very useful for separating documents into groups. Problem is, it’s not very clear what to call those groups. A cluster that was formed of documents with prominent features of ‘voltage’, ‘circuit’, ‘capacitor’ and ‘resistor’ is certainly forming a group around a specific topic, but none of the terms used to determine that make quite so good a label as the more general word ‘electronics’. There has consequently been a shift in document clustering research away from “data-centric” models that aim to make the clearest groupings to “description-centric” models that aim to create the best groupings that can be clearly labelled.
Another differentiator among clustering algorithms is when the clustering happens, before or after search. When processing search results the focus is on a postretrieval approach which lets the clustering algorithm work with the search algorithm rather than against it. Search algorithms determine which documents are relevant to the query. Since the goal of document clustering in this context is to help select among only relevant documents, it is best to find clusters within that set. If we instead consider all documents it may be that most of the relevant documents are in the same cluster and many clusters will not be relevant.
Similarly, we can leverage another part of the search system: snippet generation. Rather than just a list of documents, many search tools will include contextual excerpts containing the query terms. Here too we have a system that is winnowing the data set. Much as the retrieval algorithm limits clustering to only relevant documents, these provide candidates for the most relevant few phrases or sentences.
Carrot2
A postretrieval clustering system designed to work with short excerpts is precisely the sort that could be put to use in federated search, at least for those targets that return snippets. It just so happens that there is an open source one to play with! It’s called Carrot2 and is a Java framework for document clustering devised by Dawid Weiss and Stanislaw Osinski as an experimental platform for their clustering research and promoting their proprietary algrorithm. They provide implementations for two algorithms which I’ll attempt to summarize below but are best described in their paper A Survey of Web Clustering Engines and in more detail in some of their other research.
STC
Suffix Tree Clustering (STC) is one of the first feasible snippet-based document clustering algorithms, proposed in 1998 by Zamir and Etzioni. It uses an interesting data structure, the generalised suffix tree, to efficiently build a list of the most frequently used phrases in the snippets from the search results. This tree is constructed from the snippets and their suffixes, that is, all the snippets, all the snippets without their first words, and every sequence that ends at the end of the snippet including the last words by themselves. From this list the documents are divided into groups based on which words they begin with, with no two groups starting with the same word and no groups with only one document. In turn, each of those groups is divided by the next words in sequence. Here’s a compact example:
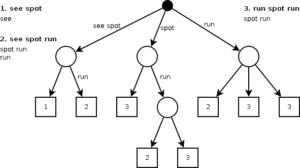
The groups generated this way form a list of phrases and associated number of snippets. Some of these phrases are selected to decide which will be the base clusters. They are ranked according to a set of heuristic rules. These rules take into account whether the phrases are present in too many or too few documents and how long the phrases are after discarding uninteresting “stop” words. Heuristics are also employed to merge clusters deemed too similar. The top few clusters are then presented to the users.
This approach is very efficient and the use of frequent phrases provides better quality labels than a purely term based technique.
Lingo
The second algorithm, Lingo, was developed as the PhD thesis of Dawid Weiss, one of the partners in the Carrot project. Lingo constructs a “term-document matrix” where each snippet gets a column, each word a row and the values are the frequency of that word in that snippet. It then applies a matrix factorization called singular value decomposition or SVD. Part of the result of this is used to from collections of related terms. Specially, they possess a latent semantic relationship. If you’re interested in the how this works, the most approachable tutorial I’ve found on the topic presents it using golf scores. A more thorough treatment on how SVD is applied to text can be found here, along with some discussion on popular myths and misunderstandings of the approach.
Grouping the words in the snippets by topic helps form clusters but does not suggest a label. To this end, Lingo uses a suffix-based approach like STC to find a list of frequently occurring phrases for use as candidate labels. Since both the collections of words and the labels are in the same set of snippets, they exist in the same term-document space. As in our earlier example of ‘fish’ being closer to ‘sushi’ than to ‘dinosaur’, there is a concept of distance here. The label closest to a collection is used. Collections without a label close enough and labels without collections are discarded. The documents with snippets matching these remaining labels then form the clusters.
Lingo improves over STC by selecting not only frequent phrases but ones that apply to groupings of documents known to be related in a way that takes into account more content than just that one phrase. STC avoids choosing phrases that are too general by discarding those that occur in too many documents, but it’s still quite possible to get very non-descriptive labels. The added precision Lingo brings with the SVDcomes at a steep computational cost as matrix operations are much slower. The authors sell a proprietary algorithm, Lingo3G, that overcomes the performance limitations.
Other approaches
Cluster analysis can be applied to a wide range of fields and all sorts of non-textual data: Pixels, genes, chemicals, criminals, anything with some qualities to group by. General techniques can usually only provide a data-driven approach to clustering text and, as discussed above, labeling is very important.
Often the best label for a cluster isn’t even in the text being clustered. Some research investigates pulling in other data to very good effect. One of the best examples of this is the idea of using Wikipedia titles. This works well because the titles of Wikipedia pages are not only relevant to the content contained therein but are in fact explicitly chosen as a label to represent that content. Search query logs are another potential source of cluster labels.
Clustering is still very much an open problem and an active research area. Even the best description centric approaches are still no match for manually assigned subject categories.